Bland Platforms: Message Reliability
Looking at some compromises and their impacts
Dec 9, 2017
I like platforms capable of going about their lives without ever getting me involved, like a good friend. Part of building a bland platform is making sure the messaging transports are incident free. I can’t hold eye contact with my scrum master, but that doesn’t mean my platform designs should also have communication issues. This blog is an exploration into identifying and mitigating potential flaws in a platform architecture with respect to message transports.
The Payload

It all starts with the payload. They are special creatures, each with their own personality, and no two are ever the same (unless they are). Understanding the payloads and their purpose should be the first step in approaching a platforms' messaging architecture.
For each journey a payload might take, it is useful to know what kind of adventure that payload ought to have by answering some simple questions.
How many payloads can be sacrificed without incident?
Data loss may or may not impact a system, and to varying degrees. If the hourly text I send to myself “you’re cool, keep it up” was dropped 10% of the time, it would only have a minor impact on my day. In contrast, I need to guarantee 100% of my outbound hate mail successfully reaches the bin or I’m in trouble.
Would a duplicate ever cause an incident?
Duplicates can appear in lots of ways and designing platforms that never duplicate requires special consideration. Alternatively, detecting and removing duplicates is also easy when planned for. Knowing if duplicates are a problem before starting a design will avoid headaches later on.
QoS: Choosing Duplicates or Drops
No one is perfect (yikes) and neither is a typical messaging protocol. They can only ever guarantee either zero duplicates - called At Most Once (AMO) - or zero dropped messages - called At Least Once (ALO).
These limitations are like grandpa’s awkward outbursts, they usually won’t be witnessed until a family gathering where tensions are already high. Both ALO and AMO protocols usually appear to be “exactly once” until the platform hits a spike of traffic or services need restarting, etc, which is when problems suddenly manifest.
Life can be made easier by picking one guarantee per transport and, if needed, designing an automated solution around the chosen limitation. It should already be known whether dupes or drops are bad. If both are bad it is best to choose ALO and use some form of deduping since drops are much harder to automatically recover. If neither is a problem then just do whatever is most fun.
Some protocols may claim to be “exactly once”. They should be treated as similar to “absolutely secure” software - be skeptical and protect against potential shortcomings anyway.
At Most Once
At Most Once describes a protocol that simply fires a message into the TCP buffer and hopes that it reaches the final destination. These protocols aren’t usually entirely blind and will often at least guarantee that a consumer exists before firing. They will not, however, resend messages under any circumstances unless a duplicate is sent manually.
AMO protocols have a number of advantages. Throughput can be relatively higher and latency can be relatively lower. Duplicates can’t spontaneously arise from the protocol. Transports are mostly stateless (data is either moving or not), which can make understanding and debugging a platform easier.
If a platform is able to tolerate a margin of loss then it is worth considering AMO, especially if duplicates would be an issue.
Some examples of higher level (not just TCP/UDP) protocols/queues that support AMO: Nanomsg, ZMQ, RabbitMQ, NATS.
It’s possible to use transports such as HTTP as AMO by simply ignoring the response codes. However, it should be noted that adding proxies and caches between services might introduce request retries, which would be no longer be AMO.
At Least Once
At Least Once describes a messaging protocol which verifies that a client has consumed a message before discarding it locally. If something were to go wrong during the transport (service crashes, network failure) these protocols will make sure the message is re-sent until it is acknowledged. Therefore, if a message is successfully consumed by a client but the acknowledgement is lost, the protocol will create a duplicate message.
Complaints from my mother are At Least Once, they will be resent until acknowledged.
ALO protocols may sound slow due to the nature of their guarantees. However, the trade off in latency and throughput is very often negligible for most purposes. Being more relaxed about duplicates can sometimes speed up these protocols as they can benefit from batch sending and verification, the risk being a higher likelihood of duplicates.
In my opinion, in order for ALO protocols to be considered ‘complete’ they ought to have the capability of persistently storing messages themselves until acknowledgement. Be aware of protocols that claim ALO but do not have persistent storage, as that makes your code the persister. If message delivery guarantees are needed then an ALO protocol is a great foundation to build a robust system on.
Some examples of ‘complete’ protocols/queues that support ALO: Kafka, RabbitMQ, NATS Stream.
If you are comfortable implementing your own persistent store for buffering unacknowledged messages then it’s also possible to use Nanomsg or ZMQ with request/reply sockets, just keep retrying messages until you receive back an agreed upon form of acknowledgement.
HTTP (and RPC protocols) also get an honorable mention here for the same reasons. However, just like with AMO you should be extra conscious of proxies or caches used as they can fuzz the concept of acknowledgement.
Why It Matters
Monitoring, tracking and fixing the source of unwanted duplicates or message drops can be a huge time sink that is entirely avoidable. It is always worth doing the research beforehand.
Like with messaging protocols, it’s worth considering platform components as either AMO or ALO and being strict about it. An ALO service using AMO protocols is capable of both dropping messages and duplicating them (the same is true in reverse). Having both drops and dupes is much harder to mitigate through design than one or the other.
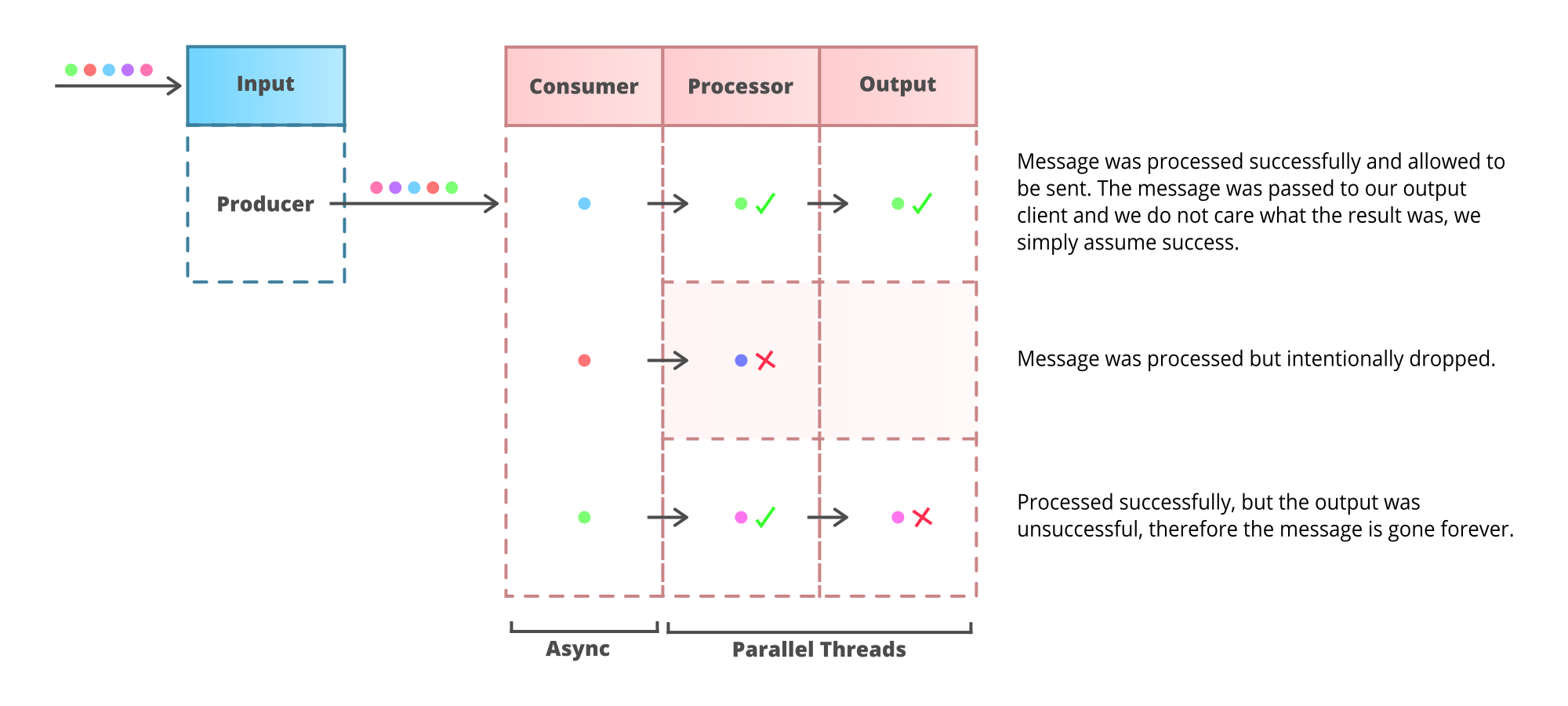
Building AMO Services
Building services that behave as AMO is fairly easy with the right mindset, just do everything lazily and it will naturally be AMO. Inputs can be entirely decoupled from outputs, making parallel processing easy.
Building ALO Services
ALO is slightly harder since an input message should only be acknowledged when it is either permanently stored somewhere or has been acknowledged by the output. Having inputs and outputs coupled so tightly means parallel or async processing has to be more strategic, but there are many ways of doing this.
If a message protocol allows a client to acknowledge messages in any order then the solution is simple. Process each message in any fashion and the exit points in the application hold responsibility for calling the acknowledgement. Be careful that the message host is configured to automatically resend unacknowledged messages after a reasonable period of time.
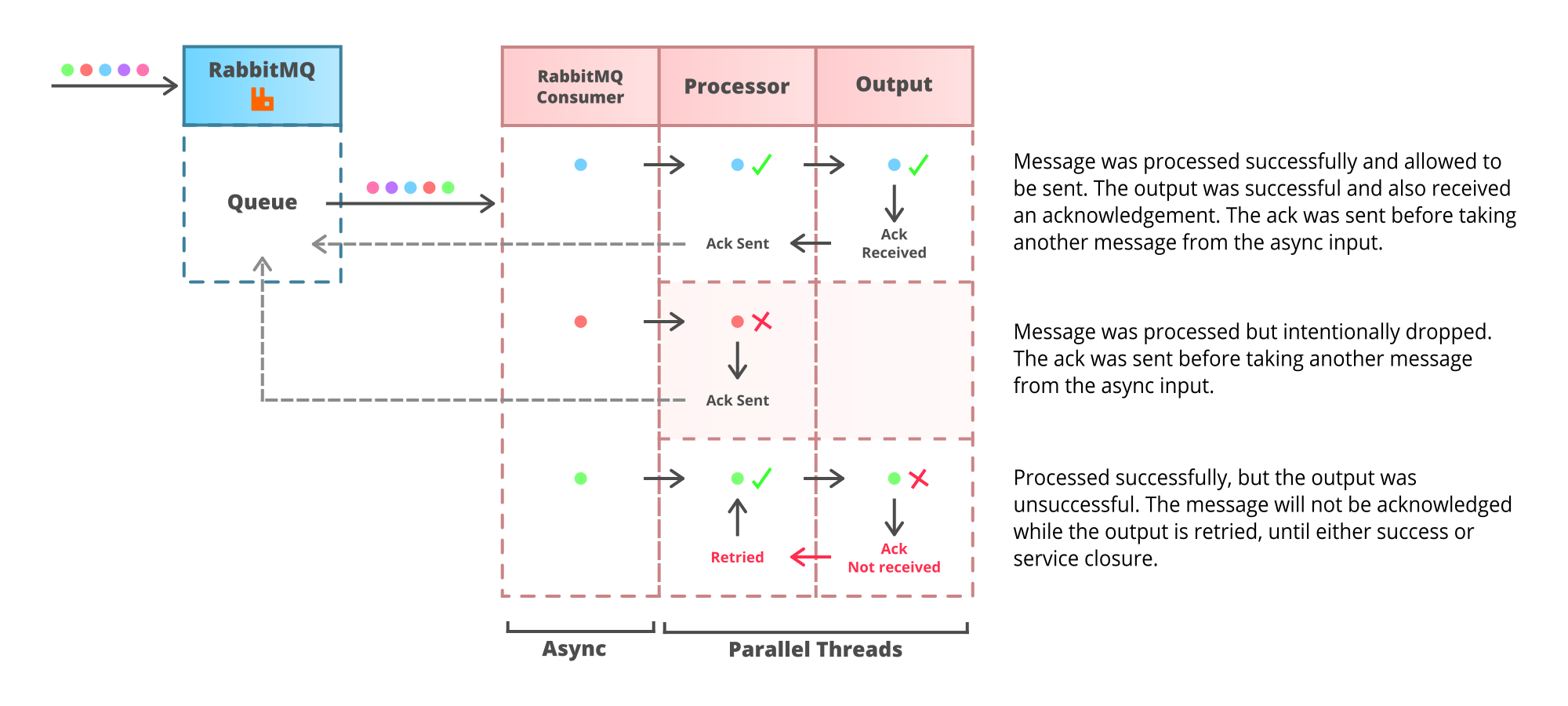
However, if the message protocol only supports consumers with a single, ordered acknowledgement (Kafka consumer group offsets, for example) then create a consumer per processing thread. With Kafka as an example it is possible to use partition balancing to evenly and dynamically distribute partitions across a consumer group per thread.
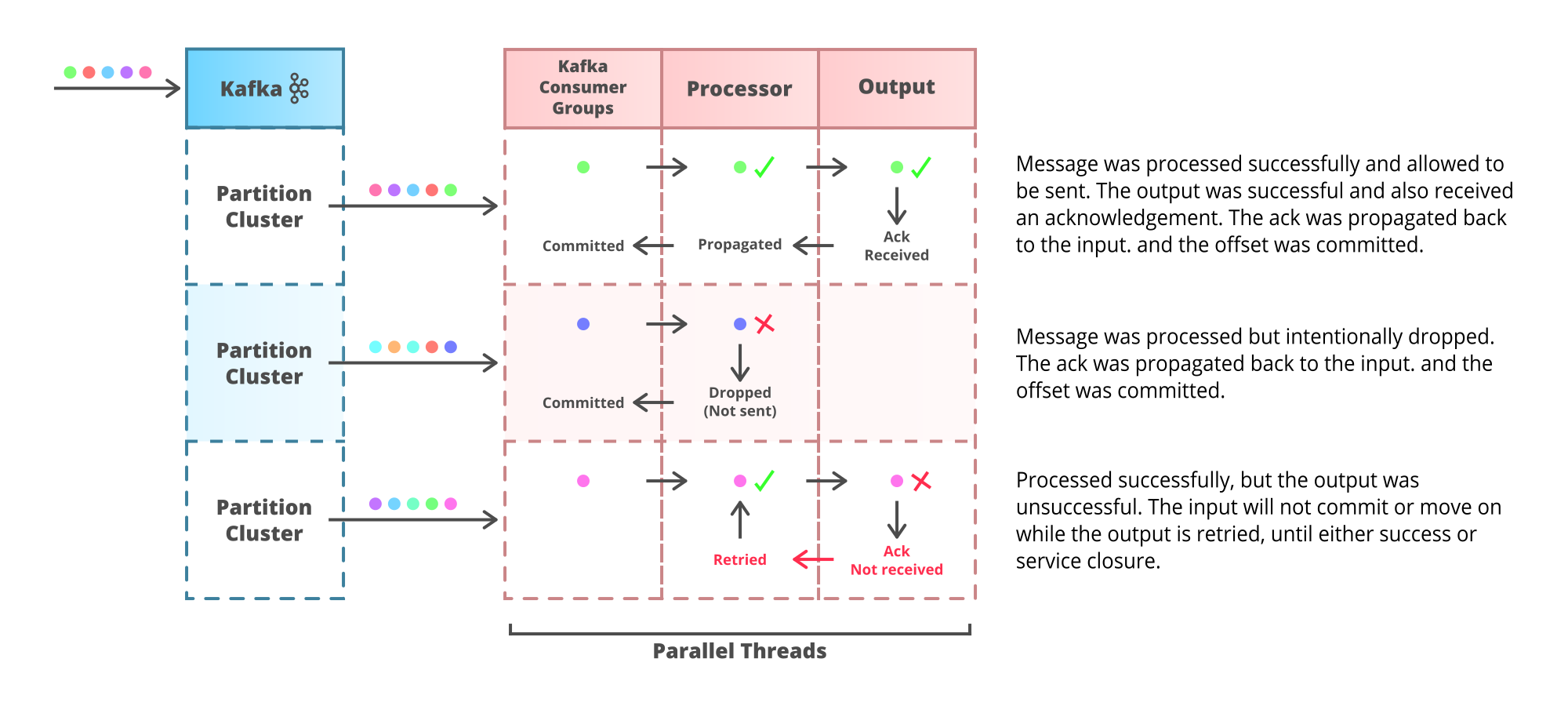
Obviously there are many ways of doing this sort of thing. Keeping plans simple and plotting the journey of messages under all potential circumstances will help keep services robust.
Ordering

It is often important that messages sent in a stream are consumed in a certain order. However, messaging protocols have many ways of screwing up order. Introducing parallel consumers for scaling purposes will also add even more opportunities for race conditions and order shuffling to occur.
All efforts should be made to design a system where the strict ordering of payloads in a message transport isn’t relied upon. A system will be more flexible and resilient if messages can be scattered freely amongst processing components without consequence.
However, it is possible to build a platform with ordered streams and multiple consumers. Messages sent through Kafka can be distributed across multiple partitions in a topic, where each partition will have preserved ordering. Consumers can then be allocated a subset of partitions to process. Messages must be partitioned in a way that isolates race conditions.
For example, if messages are user actions that must be performed in a strict order, then the partition scheme should ensure that all actions of a user will end up in the same partition. The number of partitions should also be set significantly greater than the number of parallel consumers, as the higher the partition count the more evenly the messages can be distributed.
The parallel readers in the previous example can be looked at from the perspective of message ordering:
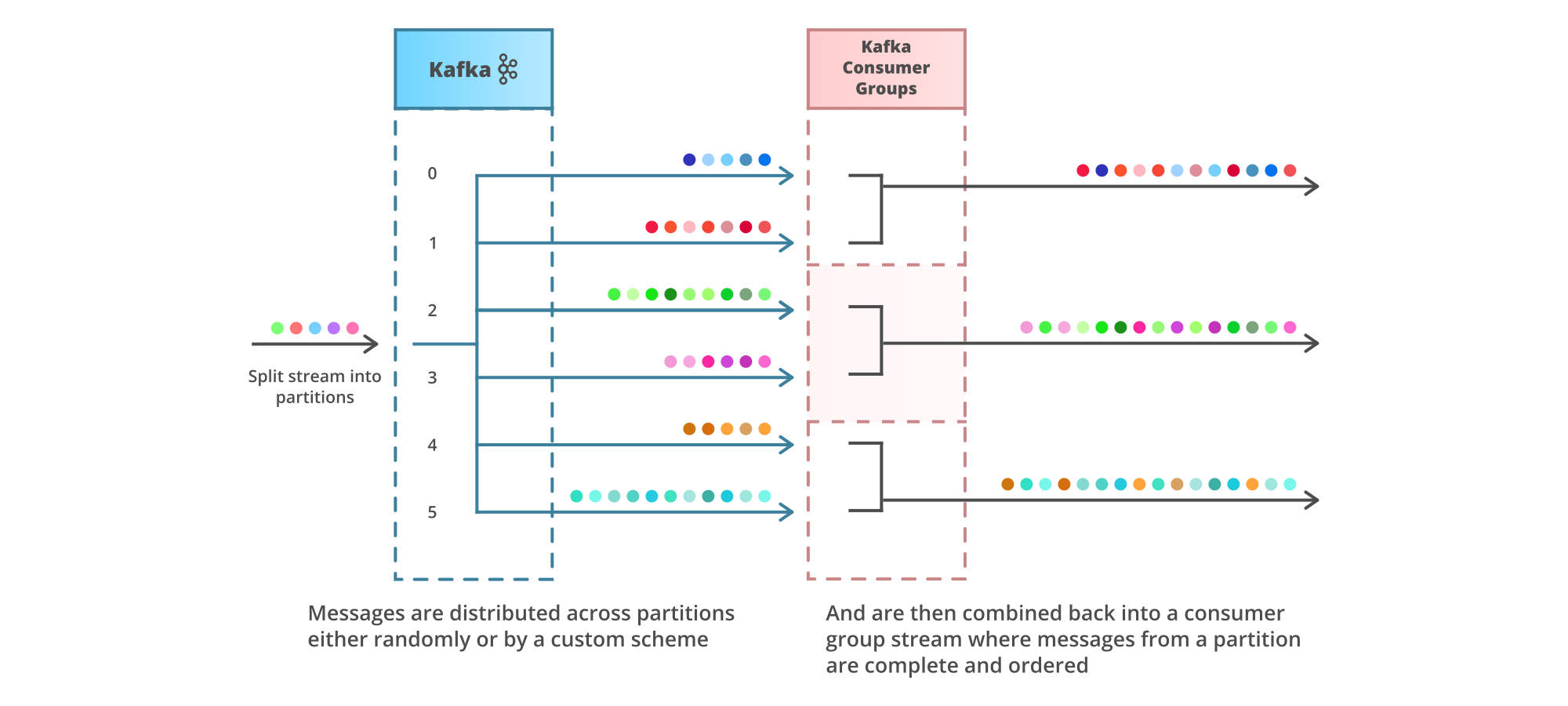
This isn’t an ideal way of distributing work amongst consumers, as partition balancing might be volatile both in raw volume and processing time for the streams, resulting in overworked consumers. Imagine if the messages in partition 0 take on average twice as much time to process as the messages in partition 3, leaving you with an uneven distribution of work.
Final Words
Building a bland platform is about trying to choose a compromise of features and guarantees that offers the best balance of stability, performance and simplicity. In order to do that it’s crucial that the compromises made and the impact they will have are fully understood.
Messaging is a critical component of platforms that also ties into other important aspects such as retention, distribution, etc. The next task will be to look at those.